基于 UI-TARS 多模态视觉模型,结合 MCP(模型上下文协议)构建下一代跨平台的自主感知 GUI Agent 智能体系统,抛砖引玉,和大家一起探讨 GUI Agent 的技术、场景和未来!
UI-TARS 工程详见 http://github.com/bytedance/UI-TARS-desktop
术语表
| 名词 | 解释 |
|---|---|
| GUI Agent | GUI Agent(图形用户界面智能体)是一类基于多模态视觉模型驱动的人工智能系统,能够自动推理并执行与图形界面(如 PC、Web、移动 APP 等)交互的任务。它可以模拟人类用户的操作,包括点击、输入、拖拽、读取界面信息等,从而自动完成用户提出的工作任务。 |
| UI-TARS | UI-TARS 是字节跳动开源一种能够自我学习的 GUI Agent ,下一代原生 GUI 代理模型,旨在使用类似人类的感知、推理和操作功能与图形用户界面(GUI)无缝交互。与传统的模块化框架不同,UI-TARS 将所有关键组件——感知、推理、反思和记忆——集成在一个视觉语言模型(VLM)中,实现端到端任务自动化,无需预定义的工作流或手动规则。详见 字节版Operator抢跑OpenAI? 直接免费开源, 网友:怒省200美元! |
| Computer Use | Computer Use 最早由 Anthropic 提出的一种基于 Claude 3.5 Sonnet 模型的新功能,允许 AI 与虚拟机桌面环境交互,执行操作系统级别的任务。 |
| MCP | Model Context Protocol*(模型上下文协议)* 是一个开放协议,它规范了应用程序如何为LLMs提供上下文。可以将MCP想象为AI应用的USB-C端口。就像USB-C提供了一种标准方式,让你的设备连接到各种外设和配件,MCP也提供了一种标准方式,让你的AI模型连接到不同的数据源和工具。详见 基于 MCP 的 AI Agent 应用开发实践 |
| UI Agents | UI Agents 技术是利用大模型技术(VLM / LLM)实现智能体对手机或电脑的自动操作,模拟人类行为完成指定任务 |
| VLM | Vision Language Models(视觉语言模型), 是指可同时处理视觉和语言两种模态的模型。 |
| MLLM | MLLM,Multimodal Large Language Model(多模态大型语言模型),它利用强大的大型语言模型(LLMs)作为”大脑”来执行多模态任务。MLLM 的惊人涌现能力,如基于图像编写故事和无需 OCR 的数学推理。 |
| SSE | Server-sent Event*(SSE,服务器发送事件)*是一种基于 HTTP 连接的技术,允许服务器实时地、单向地向客户端推送数据。对于服务器只需要向客户端推送数据,而不需要从客户端接收数据的场景,它是 WebSockets 的一个简单且高效的替代方案。 |
| VNC | VNC(虚拟网络计算)是一种图形桌面共享系统,它使用远程帧缓冲区协议(RFB)远程控制另一台计算机。它通过网络将键盘和鼠标输入从一台计算机传输到另一台计算机,中继图形屏幕更新。 |
| RPA | *Robotic Process Automation(机器人流程自动化)*是一类流程自动化软件工具,通过用户界面使用和理解企业已有的应用,将基于规则的常规操作自动化。 |
| HITL | Human-in-the-loop(HITL) 指需要和人进行交互的模型。其中人类判断被集成到自动化过程中,从而增强了人工智能系统的功能。 |
背景
为什么需要 GUI Agent?
人类使用电子设备的本质方式是什么?
- 视觉感知:通过眼睛观察和理解屏幕上的内容
- 手指操作:通过点击、滑动等手势与界面交互
- 目标导向:基于任务目标规划一系列操作步骤

GUI Agent 正是基于第一性原理,模拟人类使用电子设备的方式,实现真正的原生端到端的通用自动化。
Demo 演示
| 使用设备 | 指令 | 录屏 |
|---|---|---|
| 本地电脑(Computer Use) | Please help me open the autosave feature of VS Code and delay AutoSave operations for 500 milliseconds in the VSCode setting(请帮我开启 VSCode 的自动保存功能,并在设置中将自动保存操作延迟 500 毫秒) | 链接 |
| 本地浏览器(Browser Use) | Could you help me check the latest open issue of the UI-TARS-Desktop project on Github? (你能帮我查看 Github 上 UI-TARS-Desktop 项目的最新未解决 issues 吗?) | 链接 |
| 远程虚拟机(Remote Computer) | 识别小票内容并整理到Execl | 链接 |
| 远程浏览器(Remote Browser) | 麦当劳点一个巨无霸套餐送到鼎好 | 链接 |
| 电视(TV Use) | 播放长安的荔枝第 5 集 | 链接 |
更多 showcases 见:https://seed-tars.com/showcase
详细设计
整体概览
要完成 GUI Agent 系统,需要用到三个核心构件:
-
VLM(视觉模型): 负责理解屏幕内容和用户指令,根据用户指令+截图,生成自然语言指令(NL Command)。
-
Agent Operator(代理操作):根据用户指令,调用模型、并通过 MCP Client 来调用设备能力。本质是个流程 workflow,通过 MCP 架构解耦了 LLM 在获取不同上下文的逻辑。
-
Devices(外部设备):以 MCP Services 包提供出来,可以是 PC、Mobile、虚拟机、树莓派等,只要是电子设备都是外设,都可以接入 GUI Agent 系统中。
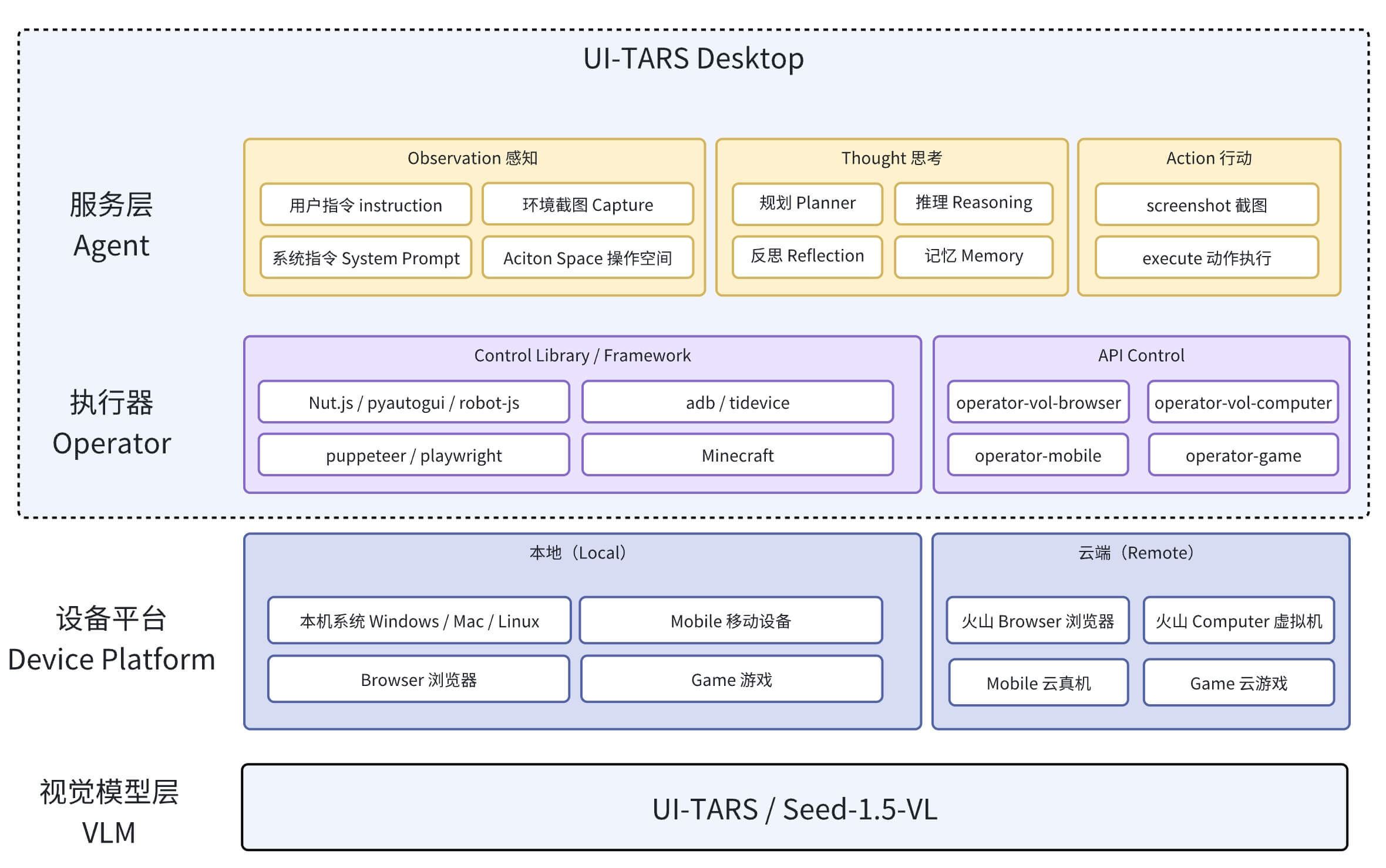
流程链路
GUI Agent 核心流程大致分为:
-
任务感知:系统接收用户通过自然语言或截图输入的指令,利用多模态模型解析并输出 NLCommand(例如:
Action: click(start_box='(529,46)'))。 -
坐标映射:将模型感知的像素坐标转成屏幕坐标
-
指令转换:将解析后的 NLCommand 转换为可执行的 Command,中间涉及到一个坐标系的转换,将图像坐标系转成屏幕坐标系,为后续的执行做准备。
-
命令执行:调用 MCP Services,将转换后的命令进行执行

前置准备
Agent 逻辑
GUI Agent 在 Agent 层主要是一个 Loop 循环逻辑,根据任务执行情况向客户端推送截图、模型输出、Action 等,所以只需要实现以下逻辑:
import { GUIAgent } from '@ui-tars/sdk';
import { NutJSOperator } from '@ui-tars/operator-nut-js';
const guiAgent = new GUIAgent({
model: {
baseURL: config.baseURL,
apiKey: config.apiKey,
model: config.model,
},
operator: new NutJSOperator(),
onData: ({ data }) => {
console.log(data)
},
onError: ({ data, error }) => {
console.error(error, data);
},
});
await guiAgent.run('send "hello world" to x.com');Operator 可任意替换成对应操作工具 / 框架,例如:浏览器控制(operator-browser)、Android 设备控制(operator-adb)等
任务感知(多模态模型)
由 UI-TARS 模型提供,定义 System Prompt,通过传入『截图』和『任务指令』,返回用于自然语言的++操作二元组(NLCommand)++,这样的好处在于和不同设备操作指令进行++解耦++。
以 PC MCP Server 提供的 System Prompt 为例:
You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
```
Action_Summary: ...
Action: ...
```diff
## Action Space
click(start_box='[x1, y1, x2, y2]')
left_double(start_box='[x1, y1, x2, y2]')
right_single(start_box='[x1, y1, x2, y2]')
drag(start_box='[x1, y1, x2, y2]', end_box='[x3, y3, x4, y4]')
hotkey(key='')
type(content='') #If you want to submit your input, use "\n" at the end of `content`.
scroll(start_box='[x1, y1, x2, y2]', direction='down or up or right or left')
wait() #Sleep for 5s and take a screenshot to check for any changes.
finished()
## Note
- Use Chinese in `Action_Summary` part.
## User Instruction
{instruction}模型输出的字段说明:
-
Action_Summary:操作的自然语言描述,带进多轮步骤 -
Action:操作名(参数)的元组
我们以 PC 端上『打开 Chrome 浏览器』任务为例,截图尺寸是 2560 x 1440,模型输出的是 Action: left_double(start_box='(130,226)'):

为什么 System Prompt click 是
[x1, y1, x2, y2]两个坐标,而不直接返回一个坐标? 早期 UI-TARS 多模态模型并不只针对 Computer Use 场景进行训练,而是在物体检测(Object Detection)、识别理解等,生成对应框 Box(x1, y1, x2, y2)。 面向 Computer Use 场景时,x1=x2 时直接复用当成同一点位,不相等时取中心点(x1+x2)/2
坐标映射
还是以上面的『打开 Chrome』为例:图像相对坐标**(130,226)是怎么算出最终的屏幕绝对坐标为:(332,325)**。
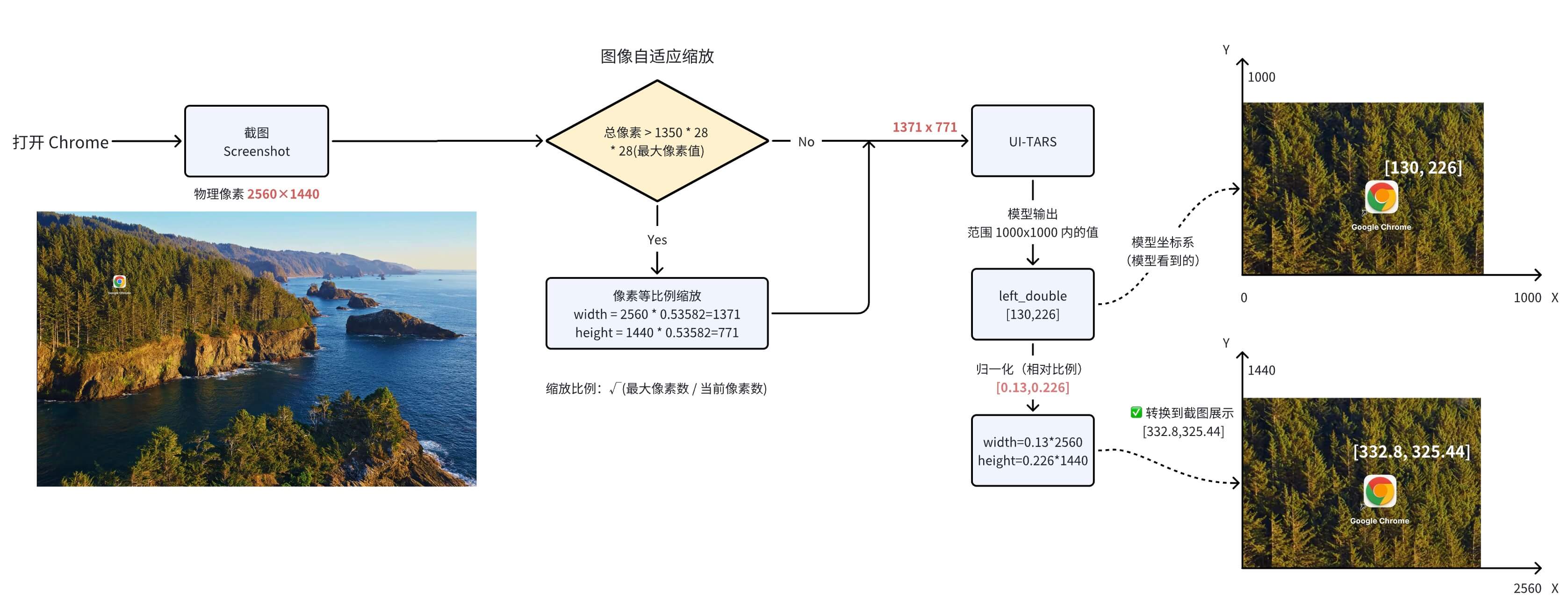
参数说明:
-
NLCommand(操作指令):模型输出的操作和坐标,模型在训练和推理时输出的是 0~1000 之间的坐标
-
factor(缩放因子):目前值为 1000(因为 UI-TARS 模型训练的坐标系是 1000x1000),对应 UI-TARS 模型输出的坐标值范围
-
width(屏幕宽度):2560px
-
height(屏幕高度): 1440px
相对坐标和绝对坐标
屏幕上的位置由 X 和 Y 笛卡尔坐标表示。X 坐标从左边的 0 开始,向右增加。与数学不同的是,Y 坐标从顶部的 0 开始,向下增加。
UI-TARS 模型的坐标系:
0,0 X increases -->
+---------------------------+
| | Y increases
| *(130, 226) | |
| 1000 x 1000 screen | |
| | V
| |
| |
+---------------------------+ 999, 999
相对坐标:(0.02, 0.247)
映射到实际屏幕的坐标系上:
0,0 X increases -->
+---------------------------+
| | Y increases
| *(332, 325) | |
| 2560 x 1440 screen | |
| | V
| |
| |
+---------------------------+ 1919, 1079指令转换
不同设备都有特定的操作指令(又可以称为动作空间),通过不同设备 operator 对应 NLCommand 转成对应设备的操作指令。
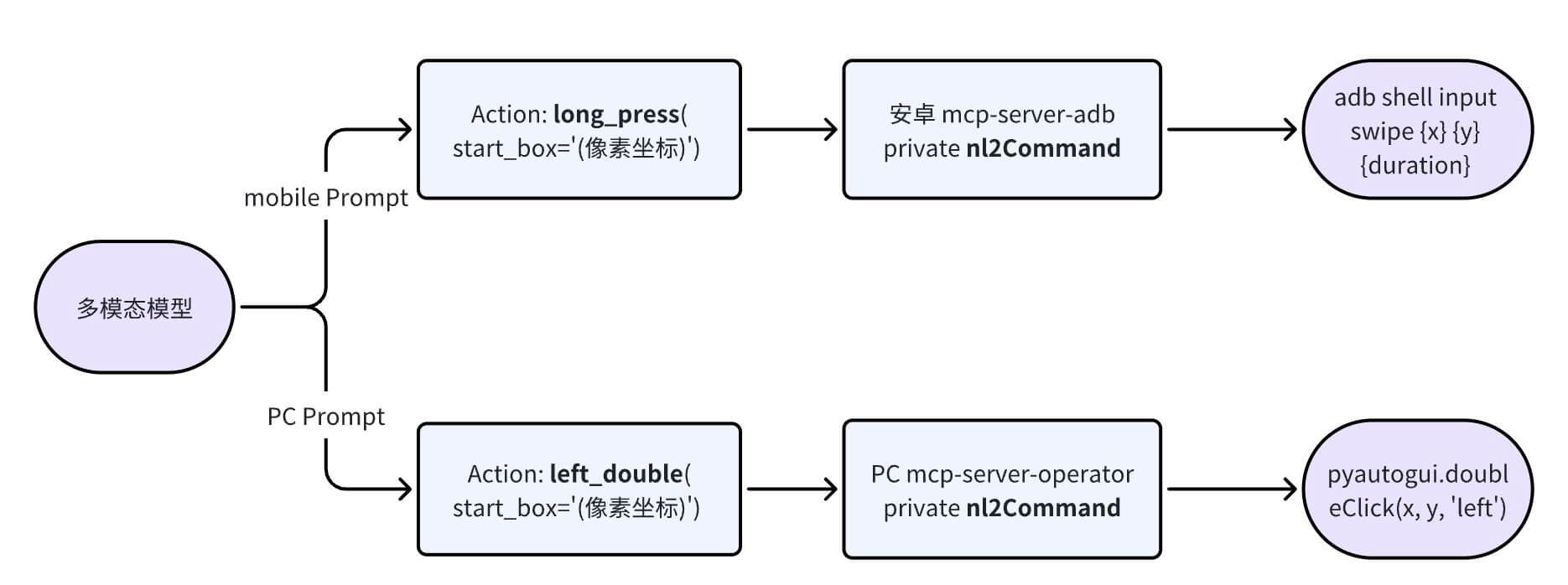
目前支持的动作空间如下:
# PC
PC = Enums[
"hotkey", # 键盘按键
"type", # 键盘输入文本
"scroll", # 鼠标滚动
"drag", # 拖拽
"click", # 左键点击
"left_double", # 左键双击
"right_single", # 右键点击
]
# Android 手机
Mobile = Enums[
"click", # 单击
"scroll", # 上下左右滑动
"type", # 输入
"long_press", # 长按
"KEY_HOME", # 返回 Home
"KEY_APPSELECT", # APP 切换
"KEY_BACK", # 返回
]不同的设备操作需要模型增加对应的训练数据,才能更好地完成对应的任务。
这一步现在有 SDK 可直接使用 @ui-tars/action-parser,调用方式见用例
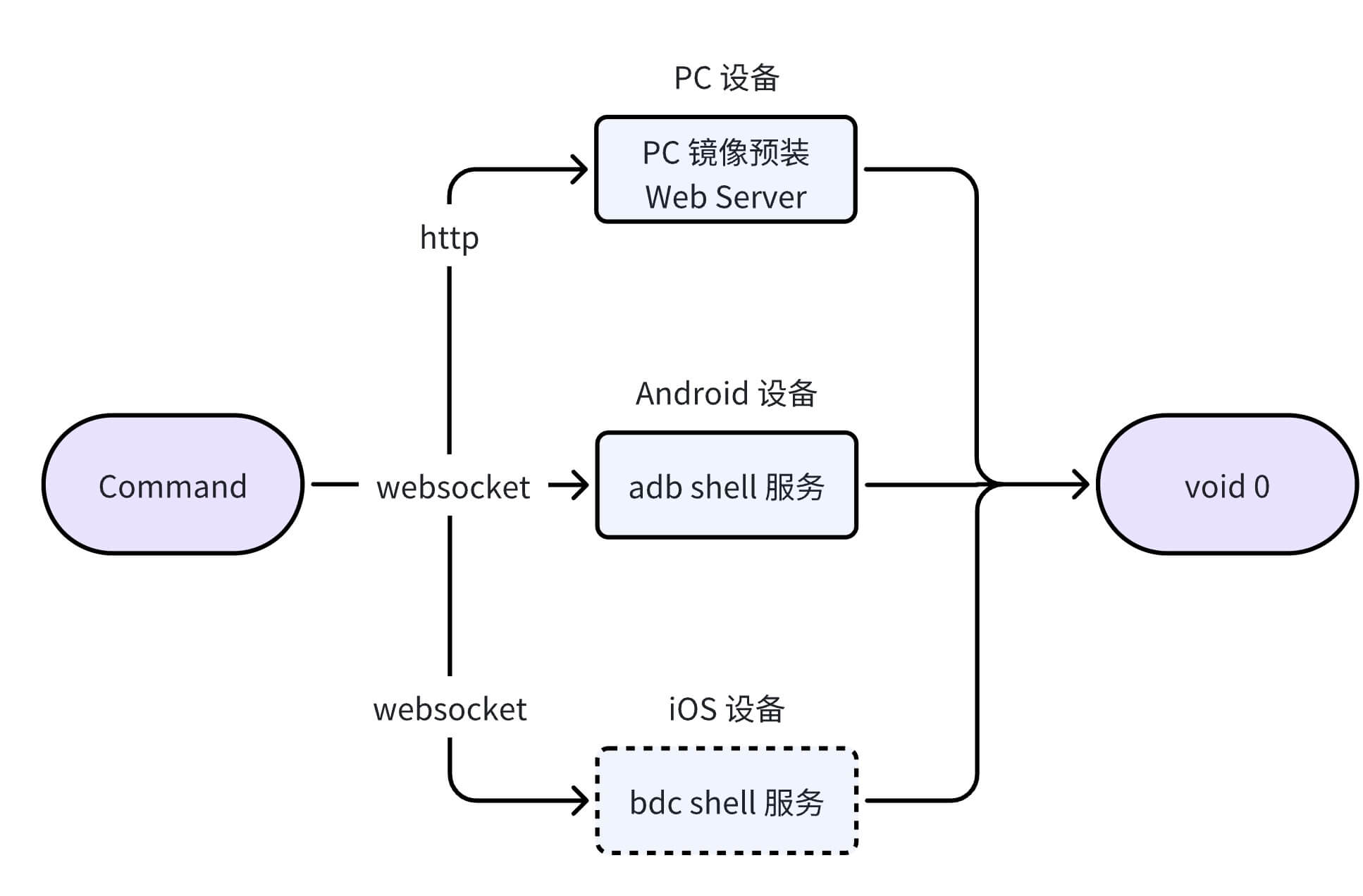
命令执行
拿到具体执行命令后,直接调用对应设备 MCP 的 execCommand 内部的方法,PC 和手机在执行远程命令执行时的流程图如下:
SDK(开发者工具)
如果对以上流程实现感到繁琐,可以使用 UI-TARS SDK 快速实现:

MCP Servers
UI-TARS 相关的 Operator 工具也支持以 MCP Server 方式提供使用:
- Browser Operator:
@agent-infra/mcp-server-browser --vision开启
思考
当前基于视觉模型的 GUI Agent 方案,第一反应想到的是 Tesla FSD 自动驾驶的技术架构演进。
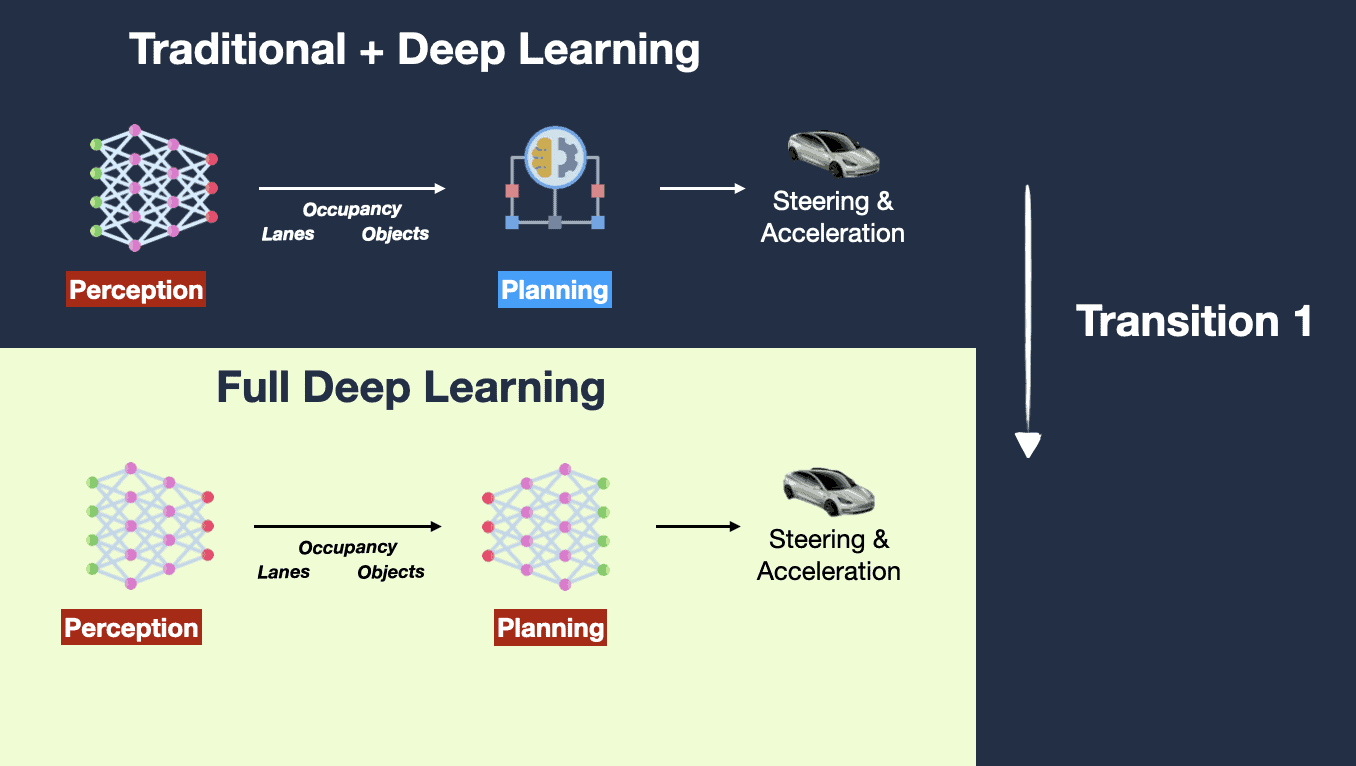
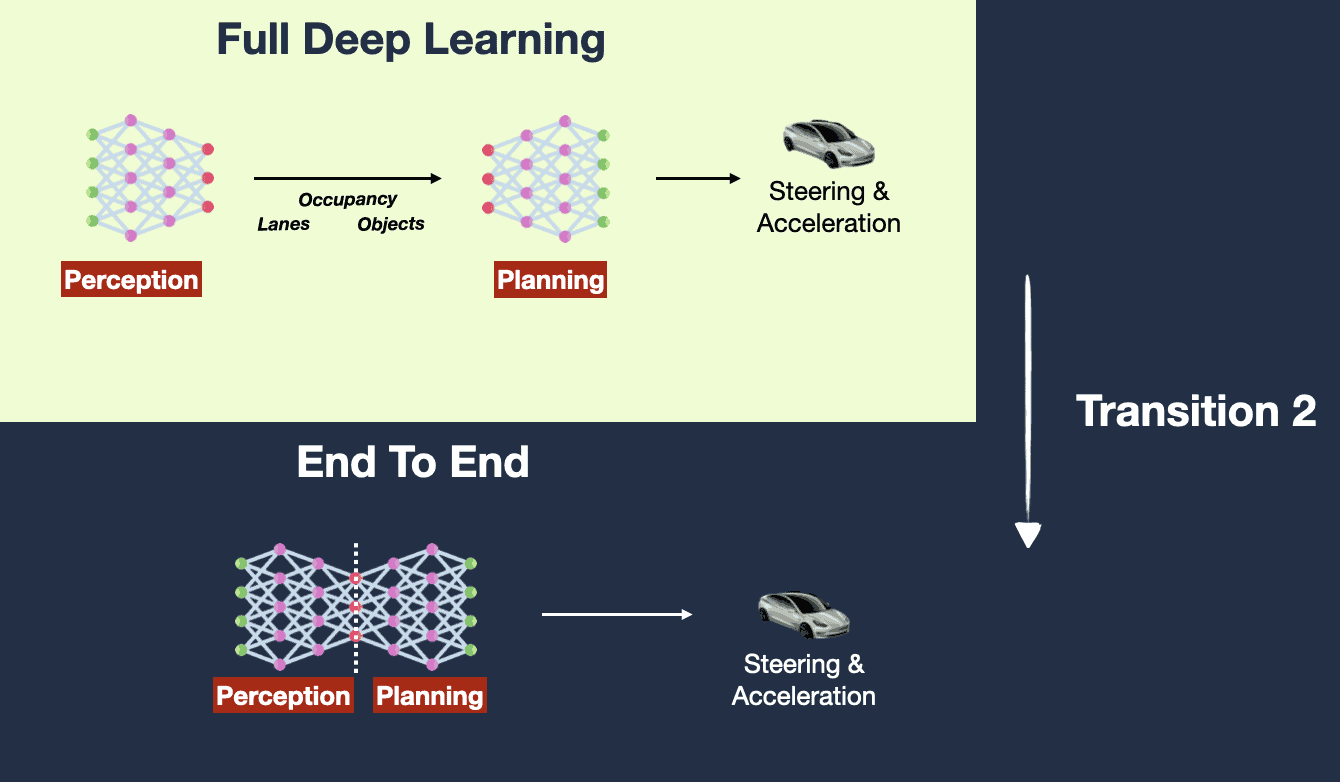
前提假设:人是通过眼睛(视觉)看到系统 UI 就可以操作,那 AI 也可以通过视觉达成。 达成条件:无限数据 + 大规模算力,直到解决所有边界 case。
基于视觉的 GUI Agent,在技术演进上的好处在于:
-
训练数据易准备:只需要『指令』和『视觉图像』,大幅度减轻了模型训练数据处理和清洗的流程。
- 如果输入再加上一个『DOM 结构』就会让模型训练陷入没有数据的困境中。
-
跨端设备易集成:设备只需要提供截图和操作两个接口,不需要获取内部 DOM 结构,方便了不同设备进行集成。
不好的点在于:
-
精准度不够:仅通过视觉就丢失了 UI 界面的层次结构(例如叠在后面的窗口、不在当前视窗的页面内容等),会造成对应的操作失准。
-
延迟高:对指令+截图的推理和识别,需要模型有更强大的推理能力,同时在执行命令时,视觉方案会转换成指令系统(pyautogui 等)进行操作,中间链路过长。
应用场景
Agentic User Testing
像人操作一样去测试应用和产品。例如 TestDriver 是一个为 GitHub 设计的异步自动化测试,可以智能生成测试用例,通过模拟真实用户行为,提供比传统基于选择器的框架更广泛的测试覆盖,支持桌面应用程序、Chrome 扩展程序、拼写和语法、OAuth 登录、PDF 生成等多种功能测试。

由此可利用 Computer Use 进行端到端的功能验证,包括检查布局完整性、元素响应情况及视觉一致性。模型能快速指出界面问题,减少人工检查工作量,检查项包括:
- 功能可用性(Availability):通过自然语言(例如:『PRD 文档』+『前端系分文档』),
- 视觉一致性(Consistency):和**『设计稿』**是否一致,通过 CV 图像识别 + 模型操作后的日志,得到结论
- 可访问性(Accessibility):无障碍检查
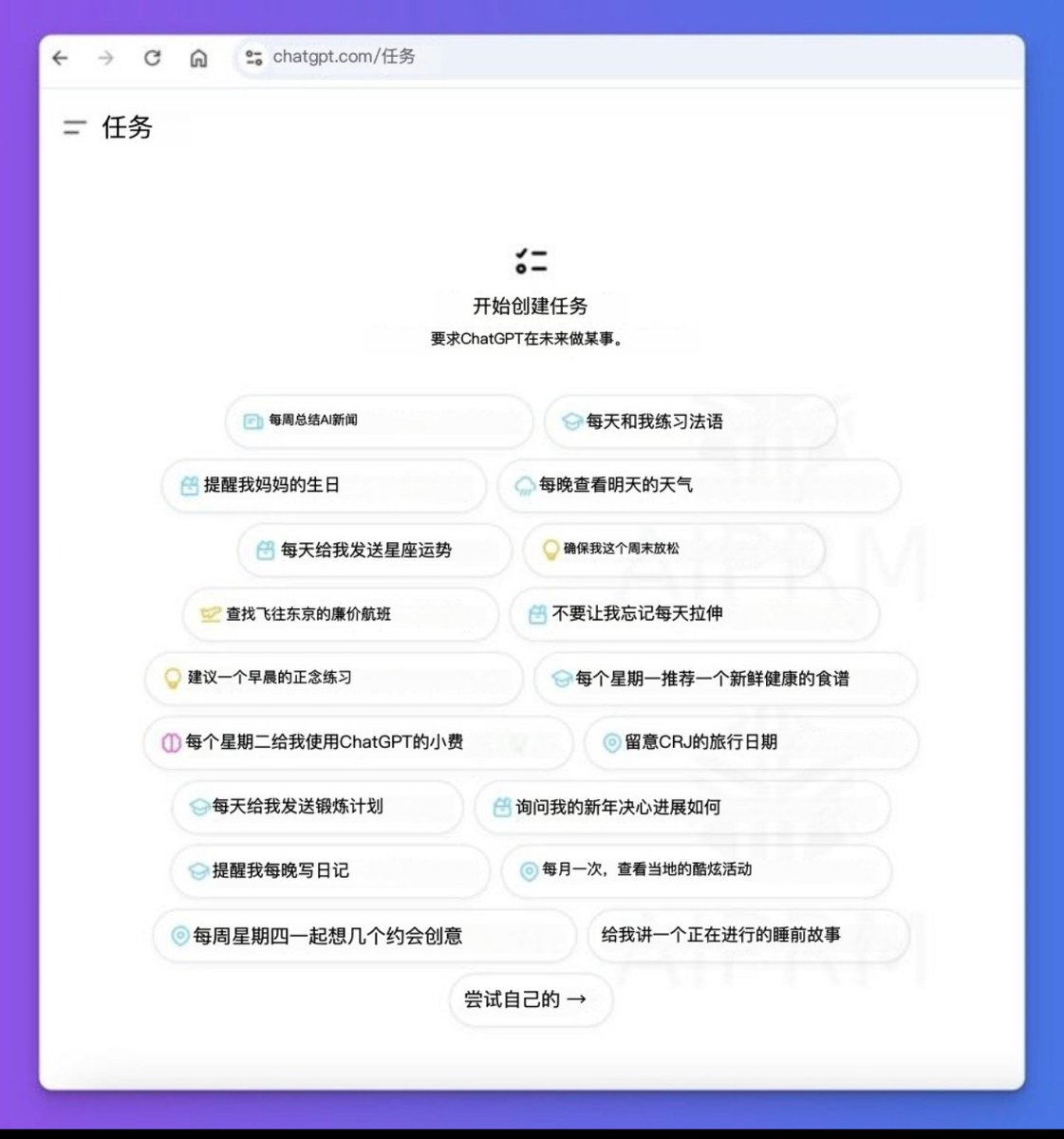
Schedule Tasks 定时任务
根据 ChatGPT Tasks 功能,可以实现『每天早上 9 点半自动打卡』的需求
C 端消费级
Computer Use 在 C 端消费级还不具备上线条件,要使用起来要解决几个问题:
- 整体响应耗时:全链路端到端做不到毫秒级,C 端商业化落地就非常困难。整体使用体验会非常割裂。
- 设备权限:截图和执行命令都是非常高的权限,除非一开始系统层内置 Computer Use。所以在 Demo 时采用了设备虚拟机,这样就有了最高权限。
- 生态集成:目前生态怎么接入 Agent 中,似乎还有共识,不过从 MCP 中看到可以标准化接入的趋势。
例如:让 AI 给我发个红包、买杯咖啡等,和直接使用 UI 操作并没有多大优势。 暂时没想到好的落地场景,更多是以『iOS 捷径』RPA 方式。未来 Computer Use 如果以 Agent 作为流量入口,通过 MCP 来集成生态(例如吃喝玩乐 APP、README 应用说明书等),倒是很有想象力。
未来
愿景
从 2013 年上映的《Her》电影来看,AI 帮人类操作计算机完成任务的科幻场景,在一步步成为现实。


新一代人机交互范式
Human-in-the-loop
当 GUI Agent 无法处理需要人帮助时,将控制权交换给人类。
这就有点像『完全自动驾驶』里的『安全员』,当 AI 能力无法处理时,人进行参与,收集边界 case 数据,不断迭代 AI。
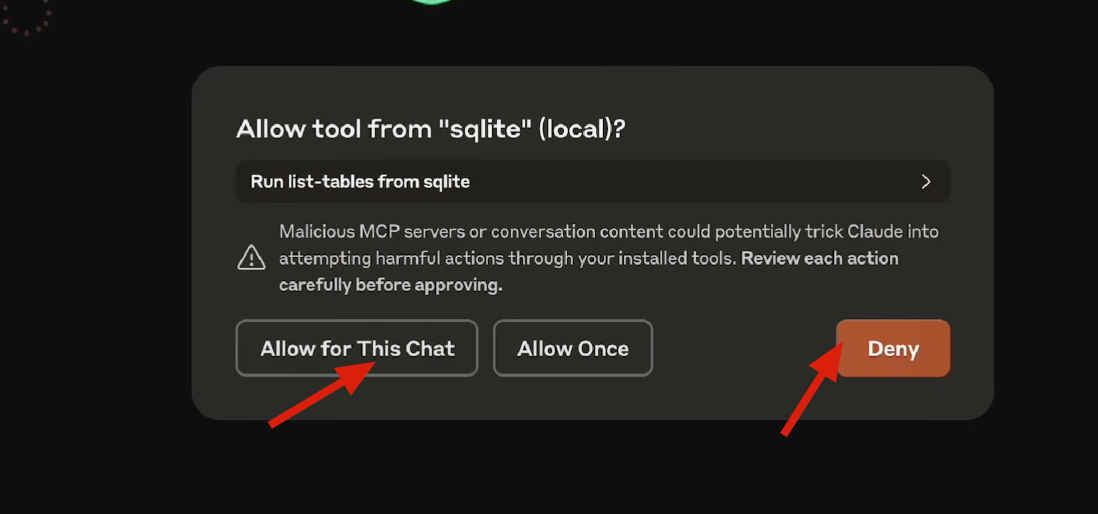
Bot-to-Bot 交互
-
与 AI 系统进行协同和交互
-
跨平台、跨系统任务传递

GUI Agent 用 AI Coding 生成贪吃蛇游戏
Q & A
为什么需要 AI 帮我操作设备?
起初我也有这个问题,AI 点咖啡不如我手动点几下,又快又不会出错。
长期来看:
- 基于『人会越来越来懒』和『AI 越来越强』这两个认知前提下,模型能力发展到达临界点,Computer/Phone Use 会极大提升用户体验。
- 那时候『人操作设备』就像『蒸汽机时代下使用马车』、『完全自动驾驶下人工』,那一天,我们会问**『为什么需要人自己操作设备?而不是用 AI』**
按自动驾驶行业的标准,GUI Agent 分级为:
| 分级 | 名称 | 定义 | 任务参与度 | 任务场景 |
|---|---|---|---|---|
| L0 | 无自动化操作 | 任务完全由人类控制,自动系统不执行任何操作。 | 人 | 所有 |
| L1 | 基本计算机辅助 | 计算机提供某些辅助功能,如自动化工具或建议,但最终决策仍由用户做出。 | 人 | 有限(例如:自动拼写检查、简单的数据输入自动填充) |
| L2(当前) | 计算机辅助执行(Copilot 阶段) | 计算机可以在特定任务中执行某些操作,但用户仍需干预或监督。 | 人(80%) + AI(20%) | 有限。例如:需要用户调整 |
| L3 | 部分自动化(Agent 阶段) | 计算机可以在更多情况下独立执行任务,但仍需要用户在特定情况下介入。 | AI(50%) + 人(50%) | 有限 |
| L4 | 高度自动化 | 计算机在大多数任务场景中能够自动处理,用户仅在特定情况下进行监督。 | AI(80%) + 人(20%) | 有限 |
| L5 | 完全自动化 | 计算机完全自主完成任务,用户无需干预或操作。 | AI(100%) | 所有 |
和 RPA 的区别?
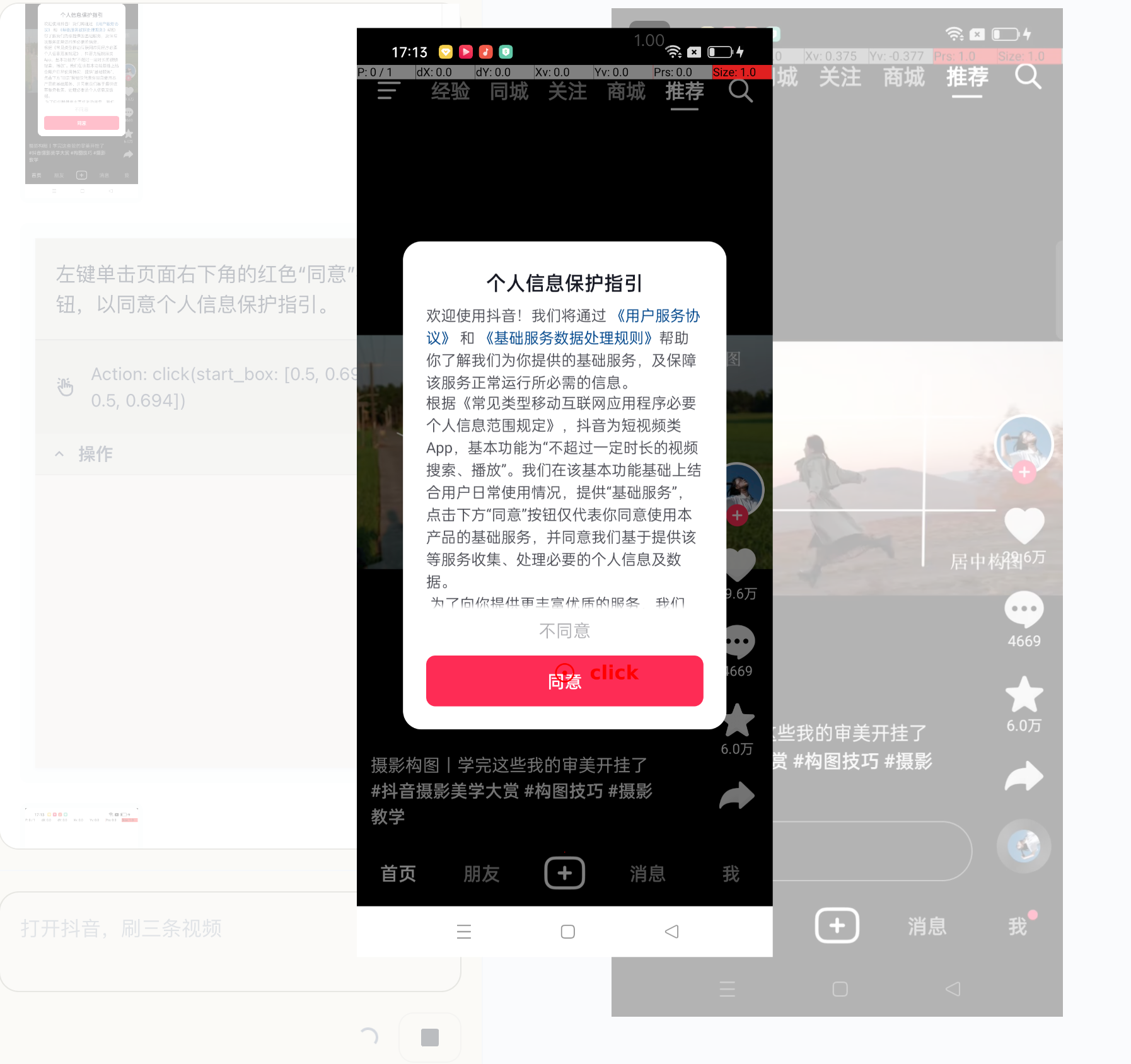
GUI Agent 是在接受『任务指令』后列出行动计划,并根据『实时的屏幕变化』进行下一步的思考、计划和操作。可以对++未知的界面++进行主动探索和试错;而 RPA 更多的是流程固定化操作,这是巨大的差异。
例如:界面突然弹窗,GUI Agent 是可以处理点『同意』或『不同意』
参考
-
Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku
-
GitHub - showlab/computer_use_ootb: An out-of-the-box (OOTB) version of Anthropic Claude Computer Us
MCP 相关:
相关论文:
-
[2501.12326] UI-TARS: Pioneering Automated GUI Interaction with Native Agents
-
[2411.17465] ShowUI: One Vision-Language-Action Model for GUI Visual Agent
-
[2410.08164] Agent S: An Open Agentic Framework that Uses Computers Like a Human
-
[2404.05719] Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
-
[2404.03648] AutoWebGLM: A Large Language Model-based Web Navigating Agent
-
[2312.08914] CogAgent: A Visual Language Model for GUI Agents
-
[2310.11441] Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V